C#で利用可能な形態素解析は、Mecabになります。
NMeCabか MeCab.DotNetの2択になります
経緯については、以下の2つを見るとよくわかります
リポジトリ移転について 2010年からOSDNで開発し公開してきたNMeCabですが、バージョン0.10.0からは、こちらGitHubで開発し公開していきます。 NMeCab MeCab.DotNet
これは何? NOTE: 将来的に、MeCab.DotNetとNMeCabを統合する作業をしています。 詳しくはこのissueを参照して下さい。 "MeCab" は、日本語形態素解析エンジンのプロジェクトです。 "NMeCab" は、上記MeCabを、.NET Framework 2.0のマネージライブラリとして実装し直したものです。ただ、もう更新されていないようです... --> GitHubで復活しました 2010年からOSDNで開発し公開してきたNMeCabですが、バージョン0.10.0からは、こちらGitHubで開発し公開していきます。 MeCab.DotNet
NMeCabは、もともとOSDNで開発されていて、.NET Frameworkが要件となっていた
その後、 別の人が .NETでも使えるように作ったのが MeCab.DotNetになります
その後、 NMeCabが OSDNから GitHubに移行し、.NETの対応を行ったため、
結論としては、 NMeCabを使えばよいという話になります
Nugetに至っては少しややこしい状況になっています。
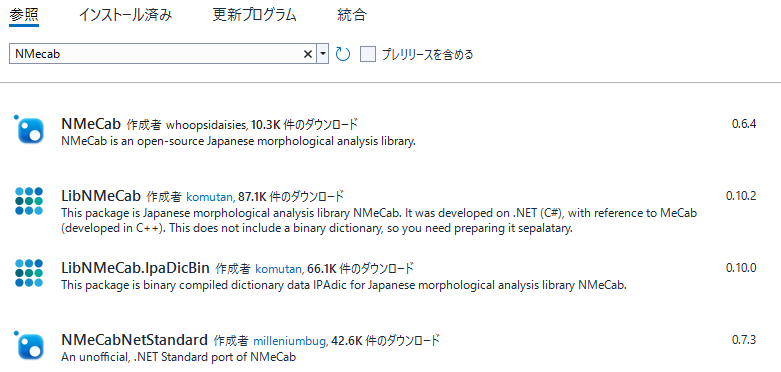
単純にNMeCabを検索すると、作者とは別の方の名前でヒットします。
これは、説明にもありますが"An unofficial package of NMecab. "
作成者の作ったものではなく別の方が作ったものになります
ずいぶん古いものがそのまま残っているのでこちらは見なかったことにしましょう・・・
では、どれをつかえばよいかという話ですが、GitHubのページの説明では
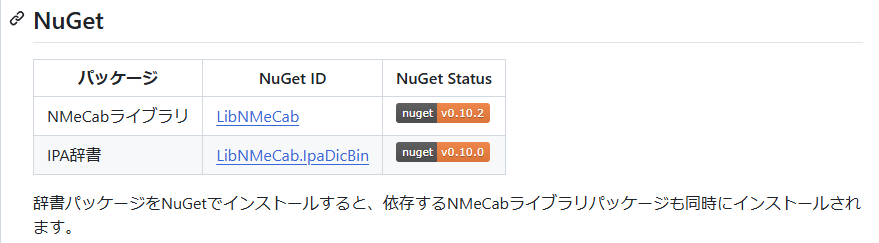
LibNMeCabが該当するライブラリとのこと
辞書パッケージを選択してインストールすると依存関係からLibNMeCabも入るよとのこと
辞書リソースは、Disposeして解放すればよいとのこと。
Taggerインスタンスが確保している辞書リソースへのハンドルを解放するのが、この Dispose() メソッドです。(.NETプログラミングに慣れない方は注意して下さい) もちろん、一度確保した辞書リソースを再利用したい場合には、usingステートメントを記述せず、Taggerインスタンスをスコープの広い変数に保持して使い回すこともできます。アプリケーション終了時など任意のタイミングでDisposeしてください。
using NMeCab.Specialized;
using System;
class Program
{
static void Main(string[] args)
{
var sentence = "「これはサンプルテキストです。」 This is a sample text.\n";
using(var tagger = MeCabIpaDicTagger.Create())
{
foreach (var node in tagger.Parse(sentence))
{
Console.WriteLine($"文字列:{node.Surface}\t読み:{node.Reading}\t品詞:{node.PartsOfSpeech}");
}
}
}
}出力:
文字列:「 読み:「 品詞:記号
文字列:これ 読み:コレ 品詞:名詞
文字列:は 読み:ハ 品詞:助詞
文字列:サンプル 読み:サンプル 品詞:名詞
文字列:テキスト 読み:テキスト 品詞:名詞
文字列:です 読み:デス 品詞:助動詞
文字列:。 読み:。 品詞:記号
文字列:」 読み:」 品詞:記号
文字列: 読み: 品詞:記号
文字列:This 読み: 品詞:名詞
文字列:is 読み: 品詞:名詞
文字列:a 読み: 品詞:名詞
文字列:sample 読み: 品詞:名詞
文字列:text 読み: 品詞:名詞
文字列:. 読み: 品詞:名詞